Abstract
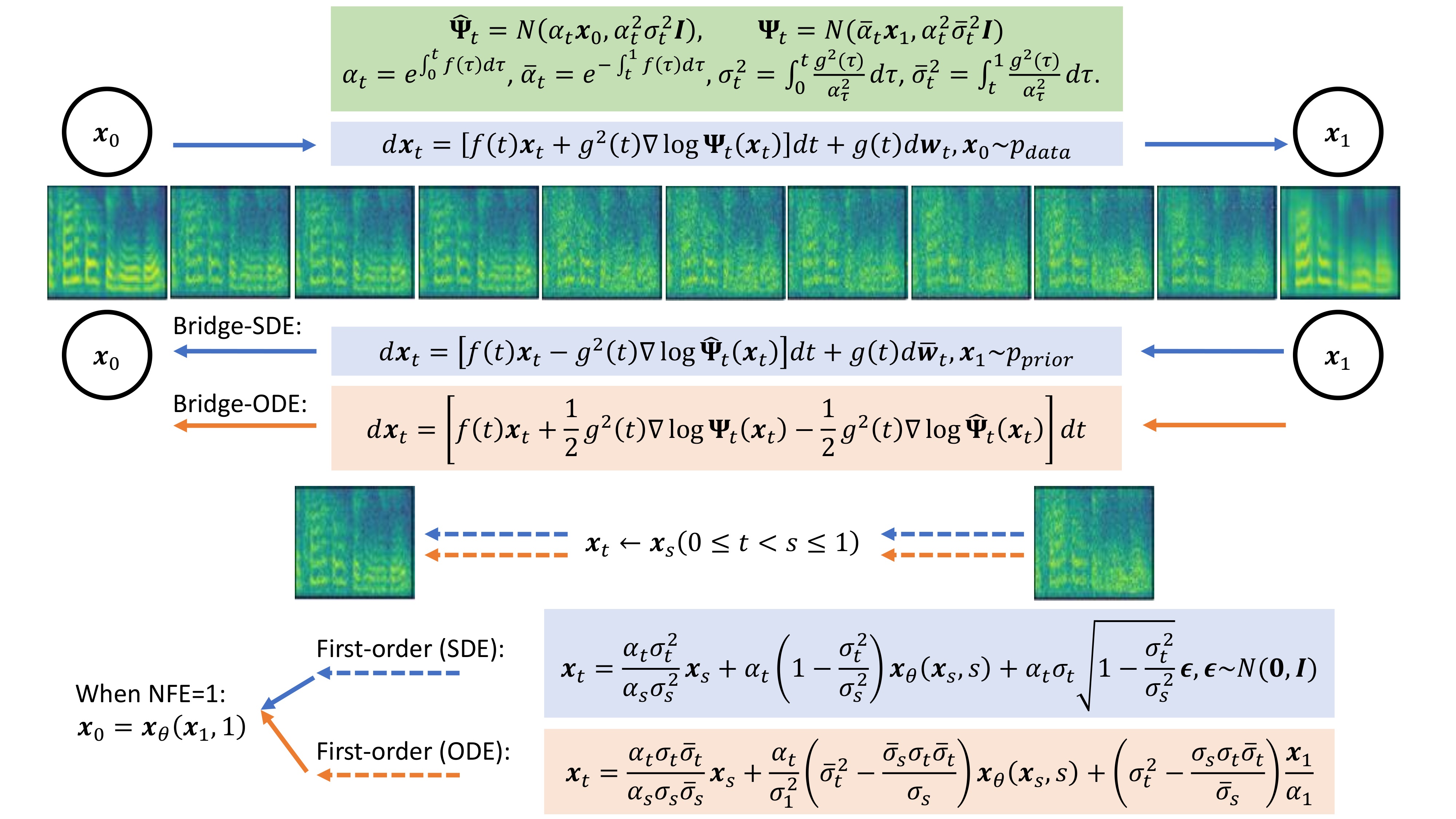
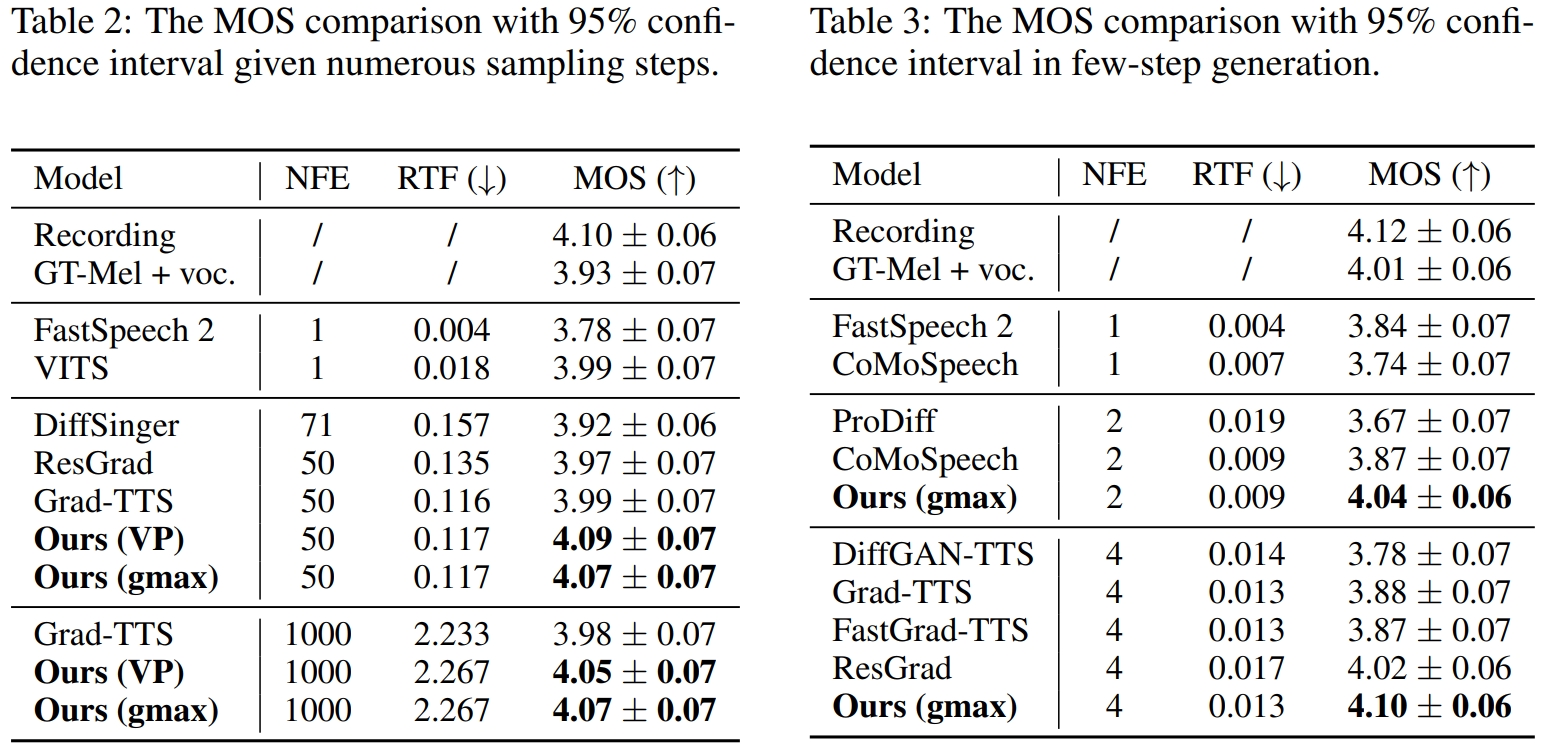
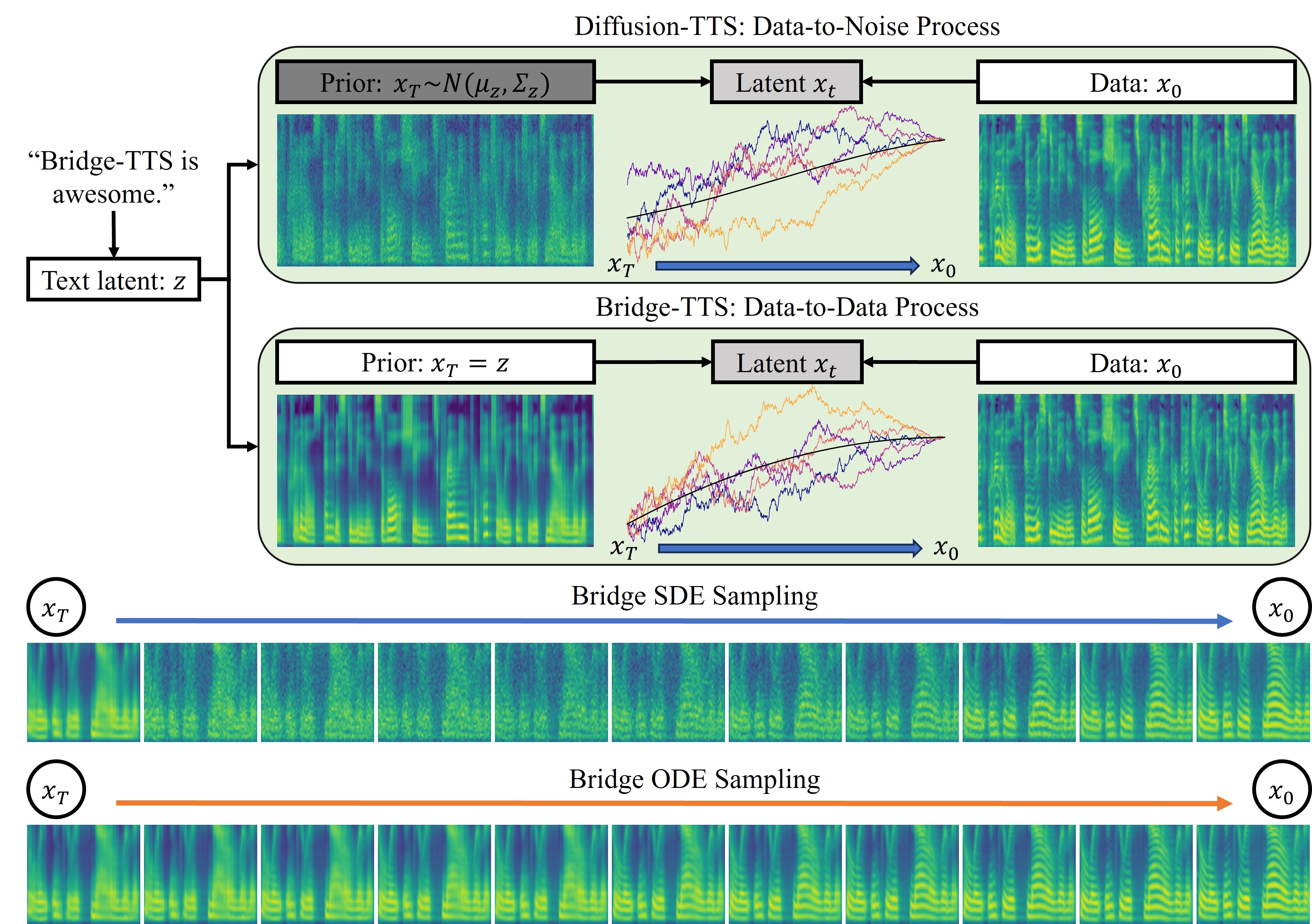
In text-to-speech (TTS) synthesis, diffusion models have achieved promising generation quality. However, because of the pre-defined data-to-noise diffusion process, their prior distribution is restricted to a noisy representation, which provides little information of the generation target. In this work, we present a novel TTS system, Bridge-TTS, making the first attempt to substitute the noisy Gaussian prior in established diffusion-based TTS methods with a clean and deterministic one, which provides strong structural information of the target. Specifically, we leverage the latent representation obtained from text input as our prior, and build a fully tractable Schrodinger bridge between it and the ground-truth mel-spectrogram, leading to a data-to-data process. Moreover, the tractability and flexibility of our formulation allow us to empirically study the design spaces such as noise schedules, as well as to develop stochastic and deterministic samplers. Experimental results on the LJ-Speech dataset illustrate the effectiveness of our method in terms of both synthesis quality and sampling efficiency, significantly outperforming our diffusion counterpart Grad-TTS in 50-step/1000-step synthesis and strong fast TTS models in few-step scenarios.